阿里的语音转文字模型 https://github.com/FunAudioLLM/SenseVoice/
听说比 openai 的 Whisper 效果好,既然是开源的,那就下载来试试看吧。
这个可以用 CPU 来运行,所以没有显卡也能用。
对电脑系统要求有 python 和 ffmpeg。
首先把代码克隆到本地
git clone https://github.com/FunAudioLLM/SenseVoice.git |
然后安装依赖
pip install -r requirements.txt |
完成后启动 webui 就可以使用了
python webui.py |
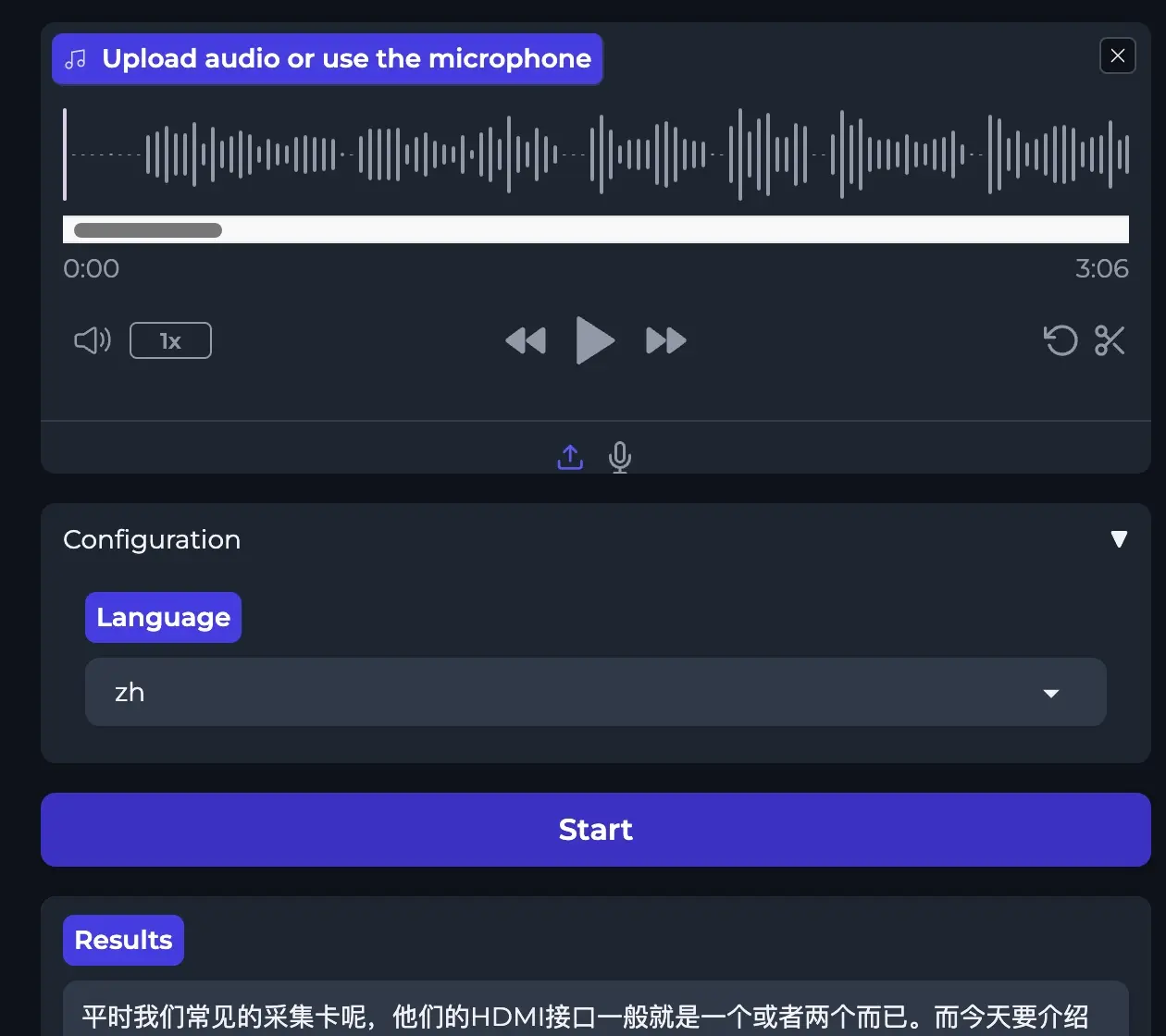
一般运行之后,会给我们一个地址 http://127.0.0.1:7860 打开浏览器访问它,然后上传音频上去,语言可以选择一下,这样可以更快速转换,再点击一下 「start」按键就可以了。
我使用的是 Mac mini,观察了一下,使用时占用内存 1.6GB,点击 start 后开始转换,主要是 CPU 占用增加,GPU 好像没变化,转换时内存占用会提高到 2.6GB。
速度确实挺快的,三分钟的音频,6 秒就转换好了。这点可以从终端看到。
time_speech: 185.867, time_escape: 6.026: 100% |
后面又尝试了一段 57 分钟的音频,耗时不到两分钟
time_speech: 3461.120, time_escape: 113.743: 100% |
注意,安装的依赖比较占用空间
torch<=2.3 |
建议创建 python 虚拟环境,专门给它使用。
我这边 venv 目录占用了 883 MB。
目前好像就开源了这个 small 模型,我们好像也不能切换其它模型,不过我感觉转换的质量还不错,所以以后在 Mac 上我就使用它来语音转文字了,Windows 上面我还是会继续使用 Whisper。